Banking is data - Automatisation de la cartographie des données (modélisation) avec des outils et de l'IA

Le mappage des données, partie centrale de la gestion des données, est un bloc de tâches chronophage et donc coûteux dans de nombreux projets bancaires.
Dans cet article, CURENTIS décrit les défis du mappage de données et examine la question de savoir si l'application d'outils et de technologies d'IA peut être utilisée pour automatiser le processus de mappage ou de modélisation des données.
Que signifie le mappage des données dans le cadre de la gestion des données ?
La gestion des données est un terme global qui fait référence à la gestion des données d'une manière structurée, efficace et sûre. Le terme "mapping de données" fait référence à la manière dont les données sont rassemblées entre différents systèmes, formats ou structures. Cela implique différents aspects, de la définition des bases de données et des tableaux à l'organisation, la maintenance, la sécurité et l'analyse des données.
Le graphique suivant illustre le processus de mappage des données :
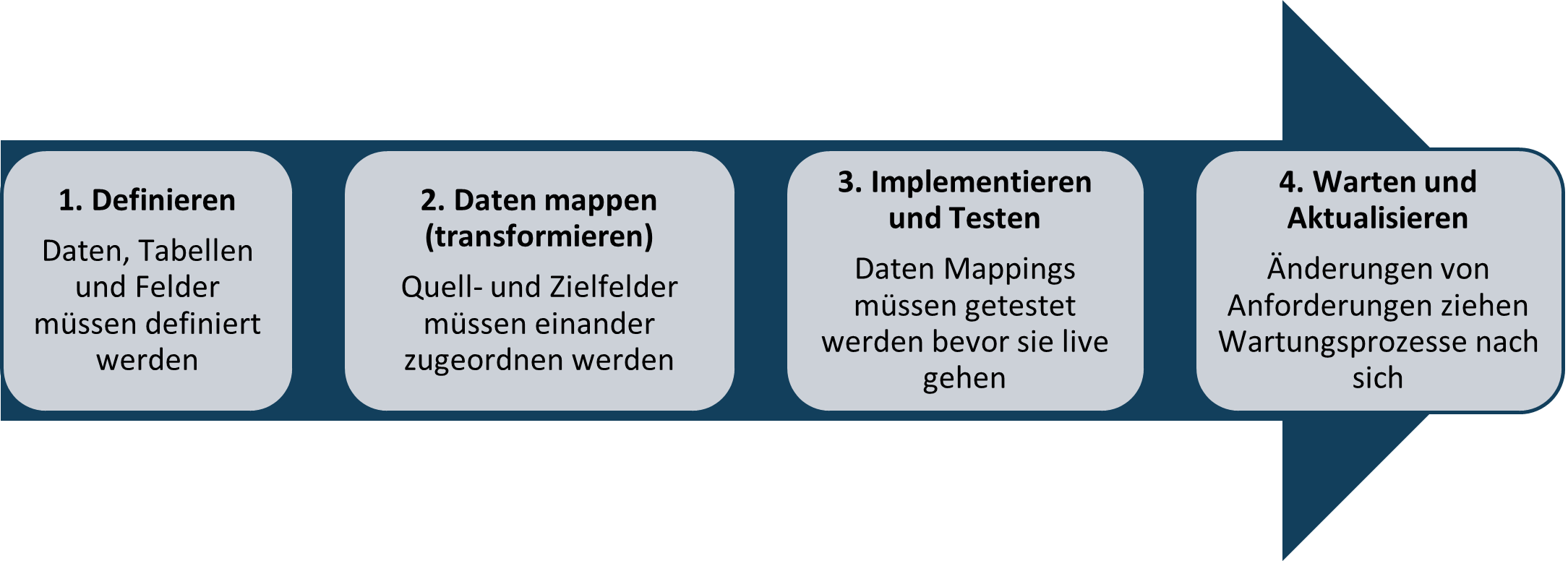
1. définir
Avant de réaliser un mapping de données, on procède à l'identification des données et à la définition des tables et des bases de données. La première étape consiste à identifier les types de données qui seront transférées entre différents systèmes ou au sein d'un même système. La deuxième étape consiste à définir les tables et les bases de données qui contiennent les données pertinentes. Cela peut inclure à la fois les tables sources et les tables cibles dans un scénario de migration de base de données.
2. cartographie des données
Le mapping de données fait référence au processus par lequel les données sont transférées ou transformées d'un modèle de données à un autre. Cela se produit souvent dans le cadre d'une intégration de données, d'une migration ou de processus de transformation. L'objectif du mappage de données est de garantir que les données puissent être transférées correctement et de manière cohérente d'un système source à un système cible.
3. mise en œuvre et tests
Une fois que le mappage des données a été conçu, l'implémentation et les tests suivent. Sur la base de la conception du mappage de données, des scripts ou des programmes sont créés pour transférer les données de la source à l'environnement cible. Cela peut impliquer l'utilisation d'outils ETL (Extraction, Transformation, Chargement), de langages de script tels que Python ou d'outils d'intégration de données spécifiques.
4. Attendre et actualiser
Il est important que les modifications apportées aux exigences en matière de données soient gérées et documentées avec soin, car une documentation à jour peut avoir un impact considérable sur l'intégrité des données et le fonctionnement du système. Un contrôle de version et une documentation efficaces sont donc essentiels pour garantir une cartographie des données cohérente et fiable, en particulier dans les environnements où les exigences évoluent. Toute modification entraîne des processus de maintenance et de mise à jour.
Un modèle de données bien conçu constitue la base des bases de données et permet de stocker, d'extraire et de gérer les données de manière efficace. Il facilite également la communication entre les différentes parties prenantes, y compris les développeurs de bases de données, les analystes et les utilisateurs finaux.
Comment l'automatisation de ce processus est-elle améliorée par l'utilisation d'outils spécialisés et d'algorithmes d'intelligence artificielle ?
- Automatisation: le processus de création et de mise à jour des mappings de données est automatisé afin de garantir l'efficacité et la précision.
- Modélisation des données: la création de modèles décrivant la manière dont les données sont mappées entre différentes sources et destinations est automatisée.
- Outils: des outils logiciels spécifiques sont utilisés pour réduire ou éliminer les efforts manuels et les erreurs dans la modélisation des données.
- L'intelligence artificielle (IA) : Des algorithmes avancés d'intelligence artificielle sont intégrés afin de reconnaître des modèles, d'apprendre automatiquement et de proposer ou de créer des correspondances de données plus précises.
L'automatisation de la cartographie des données (modélisation) dans les banques à l'aide d'outils et de l'intelligence artificielle (IA) fait référence à l'utilisation de technologies pour automatiser le processus de cartographie des données entre différents systèmes, formats ou structures.
Quels sont les avantages connus du choix des outils dans le processus d'attribution des données dans le contexte des banques ?
- Augmentation de l'efficacité: grâce à l'utilisation d'outils automatisés et d'algorithmes d'intelligence artificielle, les banques peuvent accélérer le processus d'attribution des données. Il en résulte une augmentation considérable de l'efficacité, car les affectations manuelles prennent souvent beaucoup de temps.
- Exactitude et précision: les algorithmes d'intelligence artificielle peuvent reconnaître des modèles dans de grands ensembles de données et créer automatiquement des correspondances précises. Cela contribue à minimiser les erreurs humaines et à améliorer la précision des mappages de données.
- Gérer de grandes quantités de données: Dans le secteur bancaire, il y a souvent de grandes quantités de données qui doivent être échangées entre différents systèmes. L'automatisation avec l'IA permet de traiter ces données à grande échelle.
- Adaptabilité aux changements: Les données bancaires peuvent changer en raison de modifications des exigences réglementaires ou des processus commerciaux. L'IA peut contribuer à ce que les associations automatisées puissent s'adapter à de tels changements.
- Réduction des risques: en automatisant la cartographie des données, les banques peuvent réduire le risque d'erreur humaine, notamment lors de la manipulation de données financières sensibles.
- Réaction plus rapide aux exigences du marché: La possibilité de mettre à jour rapidement et précisément les mappings de données permet aux banques de réagir avec plus d'agilité à l'évolution des conditions du marché.
- Respect des exigences de conformité: Les banques sont soumises à des exigences strictes en matière de conformité. L'automatisation du mappage des données peut aider à garantir que les données sont correctement mappées conformément aux normes réglementaires.
- Améliorer l'expérience client: Une cartographie précise des données est essentielle pour améliorer l'expérience client. Grâce à l'automatisation, les banques peuvent s'assurer que les informations sur les clients sont gérées de manière précise et cohérente.
- Intégration des sources de données: Les banques utilisent souvent différents systèmes et sources. L'automatisation permet d'assurer une intégration transparente entre ces différentes sources de données.
L'utilisation d'outils de cartographie, en particulier ceux qui font appel à l'intelligence artificielle (IA), peut présenter de nombreux avantages, mais il existe également des dangers et des risques potentiels dont il faut tenir compte. Voici quelques-uns des défis potentiels :
- Des mappages erronés: Les outils de cartographie basés sur l'IA peuvent effectuer des correspondances erronées en raison de données d'apprentissage insuffisantes ou de structures de données complexes. Cela peut entraîner des incohérences dans les données et des résultats erronés.
- Incertitude dans la prise de décision: les modèles d'IA sont souvent conçus comme des "boîtes noires", ce qui signifie que leurs processus de décision sont difficiles à comprendre. Cela peut créer une incertitude sur la manière dont certaines cartographies sont établies et sur la façon dont elles peuvent être améliorées ou corrigées.
- Protection des données et problèmes de sécurité: l'utilisation d'outils d'IA dans le processus de cartographie nécessite souvent l'accès à des données sensibles. Des problèmes de confidentialité et de sécurité peuvent survenir, notamment si les données ne sont pas suffisamment protégées pendant le mappage.
- Dépendance vis-à-vis des données d'apprentissage: Les performances des modèles d'IA dépendent fortement de la qualité et de la représentativité des données d'apprentissage. Si ces données sont biaisées ou incomplètes, les modèles peuvent être sujets à des erreurs et prendre de mauvaises décisions.
- Complexité des structures de données: les outils d'IA peuvent avoir des difficultés à traiter de manière adéquate des structures de données complexes ou des données non structurées. Cela est particulièrement pertinent lorsqu'il s'agit d'associer correctement des champs de données dans des formats différents.
- Manque de robustesse face aux changements: Des changements dans les structures ou le format des données peuvent entraîner une perte de précision des modèles d'IA s'ils ne sont pas régulièrement mis à jour ou réentraînés.
- Absence de prise en compte des règles métier: Les modèles d'IA peuvent ne pas tenir compte de manière adéquate des règles commerciales ou des exigences spécifiques à un secteur. Cela peut poser des problèmes lorsqu'il s'agit de respecter les règles de conformité ou les politiques spécifiques de l'entreprise.
- Éthique et biais: si les données d'apprentissage contiennent des biais ou des discriminations, les modèles d'IA peuvent adopter ces biais. Cela pourrait conduire à des décisions ou des actions contraires à l'éthique, en particulier lorsqu'il s'agit d'informations sensibles ou de données personnalisées.
Pour relever ces défis, il est important d'utiliser les outils d'IA de manière responsable. Cela implique le suivi des résultats, l'amélioration constante des modèles, la transparence dans les processus décisionnels et le respect des normes de confidentialité et de sécurité. Il est également conseillé d'intégrer la vérification humaine et l'expertise dans le processus de cartographie afin de minimiser les risques potentiels.
Suite aux avantages et inconvénients de l'utilisation de l'IA dans le cadre de processus de cartographie automatisés, nous présentons ci-dessous les outils de cartographie les plus populaires sur le marché et décrivons brièvement leur objectif d'utilisation :
- Talend Open Studio: (logiciel gratuit et open source) : Conçu pour l'intégration de sources de données. Il offre une interface graphique qui permet aux utilisateurs de connecter des sources de données et d'effectuer des transformations complexes.
- Informatica PowerCenter (outil Enterprise-ETL) : Conçu pour l'intégration de données provenant de différentes sources. Il offre un large éventail de fonctionnalités et une interface utilisateur simple pour faciliter le mappage.
- FME (Feature Manipulation Engine) : (puissant outil de cartographie) Conçu pour l'intégration de données géographiques. Il offre un large éventail de fonctions, y compris la possibilité de convertir et de transformer des données géographiques dans différents formats.
- Apache Nifi: (système open source pour l'intégration des données) : Conçu pour la gestion des flux de données. Il offre un large éventail de fonctionnalités, notamment la possibilité de transformer les données en temps réel.
- Altova MapForce: (outil de cartographie visuelle) : Conçu pour l'intégration de données provenant de différentes sources. Il offre une interface graphique conviviale
Dans l'ensemble, l'automatisation de la cartographie des données dans les banques contribue à optimiser le traitement des données, à garantir la précision et à améliorer l'agilité dans un environnement financier en rapide évolution. Cependant, les défis de l'automatisation du mappage des données existent et il est donc important d'utiliser les outils d'IA de manière responsable.
Compte tenu des contenus techniques présentés, CURENTIS travaille sur des solutions de conseil et de conception et soutient activement les clients dans ce domaine thématique complexe.

